“Attention Is All You Need” — How Transformers Changed Everything

The history of AI. Part 2
Why Did Recurrent Networks Fail?
In a not-so-distant world of machine learning, recurrent neural networks (RNNs) were seen as the top choice for handling sequential data. They seemed like a perfect fit for tasks related to text, audio, and time series analysis. However, the real-world results turned out to be less favorable than expected.
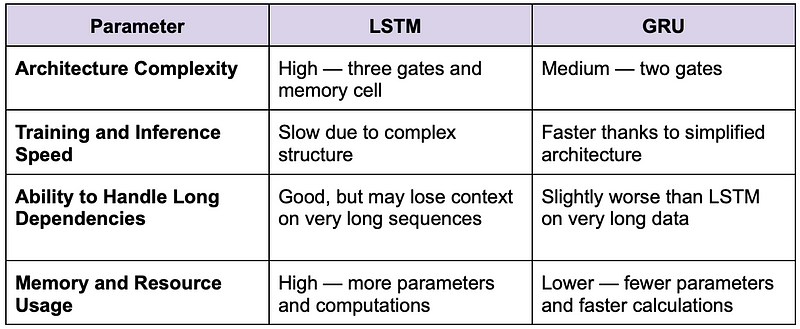
Strengths and Weaknesses of LSTM and GRU
RNNs quickly ran into problems. They forgot information. Imagine you’re starting a task, getting interrupted, and then struggling to remember what you were doing in the first place — so did RNNs. Enter LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Unit) — advanced versions of RNNs designed to tackle the issue of long-term dependencies. They improved context retention, but they weren’t without their quirks.
LSTM: Power at a Cost
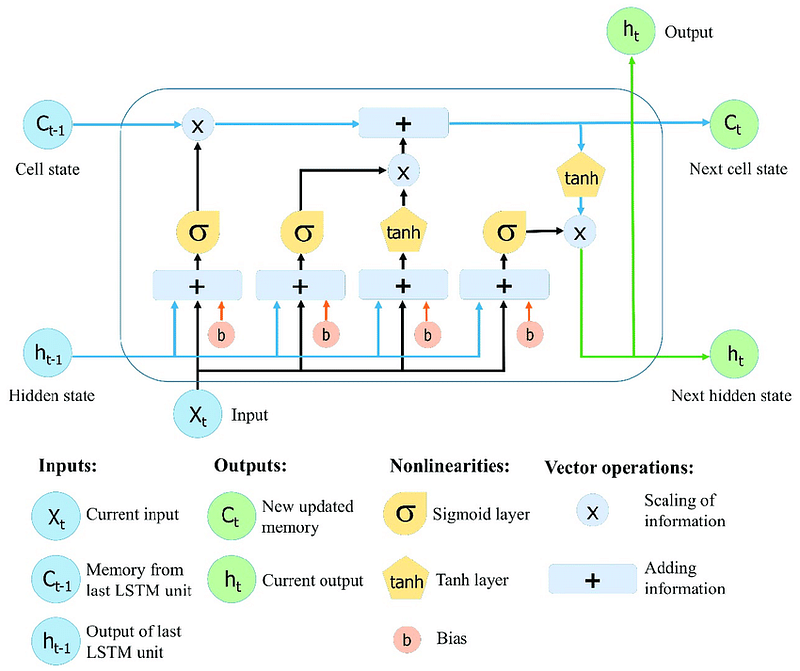
LSTMs introduced memory cells and gating mechanisms that helped them retain information over longer sequences. They could selectively remember or forget information. This made them effective in tasks like language modeling and speech recognition. For instance, LSTMs were used in Google’s early machine translation systems. Their ability to manage long-range dependencies greatly improved translation quality. However, this power came with a cost. LSTMs were computationally heavy. They required significant memory and processing power. This made them slow and resource-intensive, especially on large datasets. It’s like driving a powerful sports car that guzzles fuel. Impressive, but expensive and not always practical.
GRU: A Lighter Alternative
GRUs simplified the LSTM architecture by combining the forget and input gates into a single update gate. This made them faster and more efficient, particularly for applications where speed mattered more than subtle performance gains. GRUs were often favored in real-time applications like voice assistants. They have lower computational requirements. Think of them as the electric scooters of the neural network world: quick, nimble, and energy-efficient. However, they are not always equipped for the long haul.
Despite their improvements over standard RNNs, both LSTMs and GRUs struggled with scalability and efficiency. This paved the way for a more revolutionary approach.
Why They Struggled with Long-Range Dependencies
The Achilles’ heel of both LSTMs and GRUs is their difficulty in handling long-range dependencies. This problem arises from the infamous vanishing gradient issue. It is a mathematical challenge where the gradients used to update the network’s weights shrink exponentially during backpropagation. As a result, the farther away the relevant information is, the harder it becomes for the network to recall it.
Imagine trying to write a book review but only vaguely remembering the beginning of the story — your analysis becomes incomplete and inaccurate. Or picture trying to follow the plot of a Christopher Nolan movie when you missed the first 15 minutes — you’re lost, and so were RNNs. In real-world applications, this meant that LSTMs and GRUs often lost critical context when processing long paragraphs or extended conversations. For example, in sentiment analysis, a model might miss the sarcasm introduced early in a review and misinterpret the overall tone.
This struggle with long-range dependencies highlighted the need for an architecture that could consider the entire context of a sequence simultaneously — a need that transformers would soon brilliantly fulfill.
Transformers: The Simple Idea That Changed Everything
The Power of Self-Attention
In 2017, a paper titled “Attention Is All You Need” suddenly dropped. It introduced a concept that wasn’t about reading text the old-fashioned way, like those outdated RNNs. Instead, transformers decided it would be much cooler to look at the entire text all at once. Imagine being at a party and understanding the dynamics between every guest without eavesdropping on every conversation.
The secret sauce here is self-attention. This fancy mechanism lets a transformer decide which words matter and which can be ignored. Picture this: in the sentence, “Although the movie was long, the acting was phenomenal,” a traditional RNN would likely get lost by the time it reaches “phenomenal.” Meanwhile, the transformer recognizes that “phenomenal” relates to “acting,” not the movie’s length.
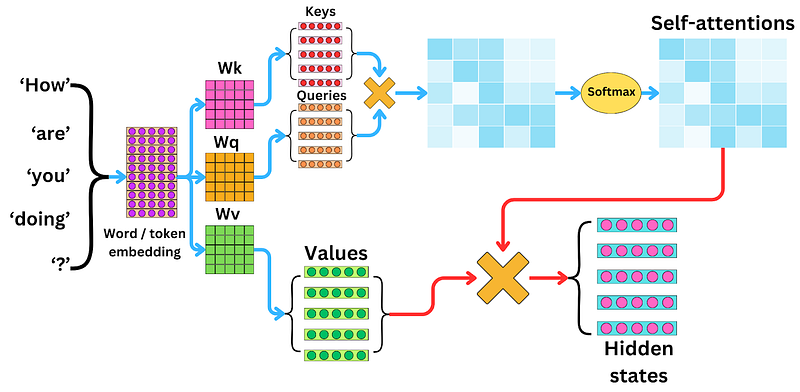
Let’s talk about its real-world magic. In machine translation, when it’s time to translate a complex English sentence into French, a transformer swoops in like a superhero. It aligns words between the two languages with jaw-dropping accuracy. It picks up on all those pesky dependencies and idiomatic expressions. In the realm of chatbots and virtual assistants, self-attention is the unsung hero. When you ask, “Can you remind me to call Sarah at 5?” the model doesn’t mix up Sarah with the time. Amazing how it can keep clarity in even the most complicated requests, isn’t it?
Why Transformers Are Faster and More Efficient
Transformers decided to ditch those old-fashioned recurrent connections. Now, they process data in parallel. It’s like realizing that multiple entrances at a concert for a blockbuster band get everyone inside faster. Instead of processing one word at a time like slowpoke RNNs, transformers tackle entire sentences — or even paragraphs — all at once. This approach dramatically speeds up both training and inference because, let’s be honest, who has time to wait?
And let’s not forget their glorious scalability. In the modern AI world, scale is everything. The more data they consume, the smarter they get. It’s almost like they have an insatiable appetite for data. Performance improves in direct correlation to model size and training data because bigger is obviously better, right? Thanks to this obsession with scale, we’ve seen groundbreaking innovations like GPT-3 with its 175 billion parameters. Google’s PaLM is pushing those boundaries even further. These models are the superheroes of text generation, creative writing, and coding. Finally, machines can write like humans!
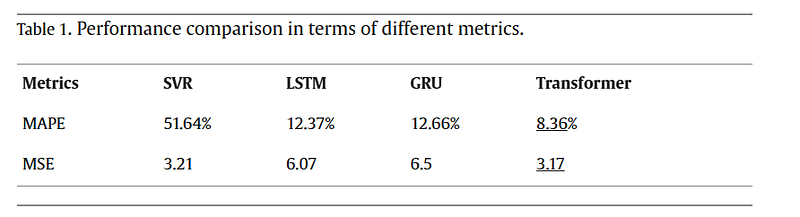
Mean Absolute Percentage Error (MAPE)
Mean Squared Error (MSE)
When a transformer-based model like GPT-3 crafts a news article from a simple headline, it doesn’t just toss words together. No, it constructs coherent, contextually rich paragraphs. Sometimes you forget you’re reading something generated by a machine. This impressive efficiency and power come from the combination of parallel data processing and self-attention mechanisms.
The Origins of “Attention Is All You Need”
2017: The Paper That Changed NLP Forever
The 2017 paper “Attention Is All You Need” was quite the game-changer in natural language processing (NLP) — or so they say. It supposedly laid down key ideas that reshaped the industry. This paper heralded the reign of transformer models. We can explore why these innovations that are considered critically important:
- Self-attention mechanism: Unlike those slow RNNs that crawl through words one by one, self-attention lets the model absorb the whole context at once — what a game changer! In the sentence “The cat, despite the dog’s barking, calmly sat on the mat,” self-attention effortlessly connects “cat” and “sat,” even with all those words in between. This magical knack for grasping long-range dependencies truly makes transformers the reigning champions of language tasks.
- Removal of recurrent connections: By ditching recurrence, transformers overcame the slow, step-by-step nature of RNNs. Imagine trying to read a book where you can only turn one page at a time after fully processing the previous one — that’s how RNNs worked. Transformers, on the other hand, are like flipping through the entire book at once, immediately seeing patterns and connections without waiting for each individual page.
- Parallel data processing: This is where transformers truly shine in terms of efficiency. Because they process sequences in parallel, they train much faster and handle much larger datasets. For example, training an LSTM on Wikipedia could take weeks — because who doesn’t love a good wait? Meanwhile, transformers dash in, outperforming it in no time. Enter GPT-3, scaling to incredible sizes and capabilities — just what we need.
These three innovations turned out to be the perfect formula for creating faster, more efficient, and more powerful language models, making the transformer architecture the undisputed king of NLP.
Why Transformers Outperformed LSTM
If LSTMs are the old reliable desktop computers — sturdy, dependable, but slow — transformers are the sleek, high-end gaming rigs with liquid cooling, custom builds, and enough processing power to run Cyberpunk 2077 on max settings without breaking a sweat. They’re faster, smarter, and more efficient — because, of course, we’ve reached a point where we need machines that can outsmart humans. The self-attention mechanism is like having a superpowered strategy gamer who can survey the entire battlefield while the rest of us are still figuring out the rules.
Take the sentence “Despite the heavy rain, the football match continued without interruption.” A transformer just breezes through it, automatically connecting “rain” and “continued,” as if it’s some grand revelation that the rain and game aren’t exactly best pals.
This global view helps transformers excel in complex language tasks like machine translation, text summarization, and question answering. In real-world applications, that’s why Google Translate went from being a punchline to an actually useful tool — because transformers enable it to understand nuance and context that older models couldn’t handle. Unlike LSTMs, which often stumble when dealing with long-distance dependencies, transformers maintain clarity even when parsing paragraphs of intricate, nuanced information. This efficiency and accuracy are why transformers have become the backbone of modern AI applications, from voice assistants to code generation tools.
The Evolution of Transformers: From BERT to GPT
Google BERT: The First Transformer-Based NLP Model
BERT (Bidirectional Encoder Representations from Transformers) was the first widely recognized transformer model capable of understanding text bidirectionally. Unlike traditional models that processed language one word at a time in a single direction, BERT took a revolutionary approach. It reads text both forwards and backwards, because apparently understanding context isn’t just a nice-to-have. Take the sentence “The bank was flooded after the heavy rain.” BERT decides whether “bank” is a fancy financial institution or just a soggy riverbank by glancing at the words around it. This whole bidirectional thing is what made BERT the rock star of question answering and sentiment analysis.
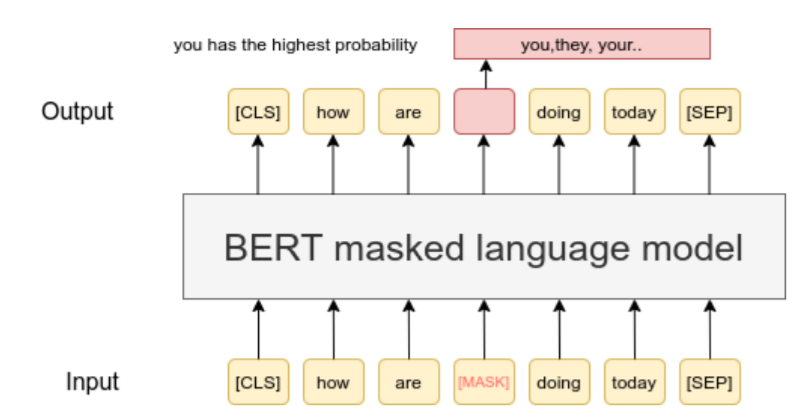
Naturally, BERT’s brilliance didn’t go unnoticed. Google jumped on the bandwagon, throwing BERT into its search engine algorithms like it was the missing piece to a puzzle no one knew existed. Suddenly, search results got a makeover, because we all know that users definitely needed help figuring out what they meant. Take a query like “2019 Brazil traveler to USA need visa.” With a heroic leap, BERT interprets the prepositions and identifies that it’s about a Brazilian heading to the USA, not the other way around.
OpenAI GPT: Why Generative Models Dominated
While BERT was busy mastering the nuances of language, OpenAI’s GPT (Generative Pre-trained Transformer) decided to take a leap into the land of human-like text generation. These GPT models, trained on mountains of text data, can whip up coherent, contextually relevant writing faster than you can say “artificial intelligence.” It’s almost like they think they can write essays and poetry.
One of GPT’s standout features is its ability to keep track of context over long passages. So, when you throw a charming prompt like “Write a story about a detective solving a mystery in space,” GPT doesn’t just stop at simple story. It crafts a detailed, imaginative narrative with characters and everything. This flair for creative, context-aware generation has made models like GPT-2 and GPT-3 the darlings of chatbots, content creation, and automated customer service.
GPT’s dominance also stems from its scalability. We jumped from 1.5 billion parameters in GPT-2 to a whopping 175 billion in GPT-3. More numbers equaled more sophistication. Now these models can generate text that almost rivals human writing. Almost.
Further Developments: GPT-2, GPT-3, T5, PaLM, and More
The evolution of transformers didn’t peak with BERT and GPT. Google presented T5 (Text-To-Text Transfer Transformer), where every problem — translation, summarization, question answering — became a simplistic text-to-text task.
Then came Google’s PaLM (Pathways Language Model), which pushed boundaries even further and set new benchmarks for language understanding and generation. With its massive scale, it tackled logical reasoning and commonsense understanding.
These endless advancements have secured transformers as the reigning champions of modern AI, powering everything from automated writing assistants to coding whizzes like GitHub Copilot. With models getting larger and more powerful, the possibilities seem — dare I say — limitless!
Wrapping Up
Transformers have become the foundation of modern artificial intelligence, reshaping the landscape of machine learning and redefining what’s possible in text, sound, and image processing. From Google’s BERT revolutionizing search engines to OpenAI’s GPT generating human-like text, transformers have consistently pushed the boundaries of innovation and efficiency.
But as powerful as they are, transformers come with their own set of challenges. Their insatiable hunger for massive computational resources and enormous datasets makes them difficult and expensive to train. Even with their remarkable capabilities, issues like model interpretability, bias, and environmental impact remain unsolved puzzles. Additionally, their reliance on a fixed context window limits their ability to process and recall long-range dependencies, posing challenges for tasks requiring deep contextual understanding. As we stand on the shoulders of these AI giants, the question arises: what’s next? Perhaps the next breakthrough is already taking shape in the form of more efficient architectures, hybrid models, or entirely new paradigms that will take AI to even greater heights.