The Age of LLMs: Reigning Champions or Doomed Titans?

The history of AI. Part 3
Artificial intelligence used to be the realm of wild sci-fi dreams. We imagined sentient machines plotting world domination or giving ominous warnings in robotic tones. While we haven’t reached the stage of “kneel before your AI overlord,” Large Language Models (LLMs) are now the stars of the show. They are reshaping industries with their impressive ability to generate text, code, and even poetry. Fueled by trillions of parameters and an endless hunger for data, they have become the crown jewels of modern AI. But where does this journey take us? Is there a speed bump labeled ‘caution: unintended consequences’ just around the corner?
Why Large Language Models (LLMs) Dominate AI Today
If AI were an Olympic sport, LLMs would be the undisputed champions, racking up gold medals in text generation, coding, and even creative writing. The battle for AI supremacy has drawn in every tech titan — OpenAI, Google DeepMind, Meta, Anthropic — each wielding increasingly sophisticated models. OpenAI’s GPT-4 Turbo, for example, boasts trillions of parameters and is already powering everything from chatbots to enterprise applications. Google’s Gemini aims to seamlessly integrate with search and mobile platforms, while Meta’s LLaMA 3 is pushing the boundaries of open-source AI. Even newcomers like Deepseek, Qwen and xAI’s Grok are joining the fray, proving that the field isn’t limited to just the Silicon Valley giants.
What makes LLMs so dominant? They’ve cracked the code on human-like text generation, effortlessly drafting essays, debugging code, translating languages, and even generating passable stand-up comedy routines. GPT-4 can help write legal contracts, Claude 3 can summarize complex documents with remarkable accuracy, and Gemini’s multimodal capabilities allow it to analyze both text and images in real-time. The real secret sauce? Scaling. More data, larger models, and an insatiable hunger for computing power — some models require thousands of high-end GPUs running for weeks just to train. It’s a race where the currency isn’t just innovation but raw computational muscle.
How Do Large Language Models Work?
Back in the day, early AI models were like enthusiastic but clueless interns — good at following instructions but lacking any real depth. They excelled at simple tasks like rule-based chatbots or basic language translation but crumbled under anything requiring nuance, memory, or reasoning. Enter transformers, a revolutionary architecture introduced in 2017 by Vaswani et al., which fundamentally changed the game. Unlike their predecessors, transformers use self-attention mechanisms to weigh different words in a sentence, allowing them to understand context more effectively. This breakthrough paved the way for models like BERT, T5, and eventually the LLM giants we see today, such as GPT-4 and Claude 3.5.
Scaling became the magic word. But scaling isn’t just about bigger models — there’s also a growing trend towards self-hosted AI solutions. Companies wary of data privacy regulations are increasingly looking at on-premise AI deployments. Nvidia’s investment in local AI hardware and platforms like BeaveRAG.ai, which enables self-hosted AI applications, are clear indicators of this shift. Google’s PaLM, for instance, demonstrated that larger models trained on massive datasets could achieve near-human performance on a wide range of language tasks. OpenAI’s GPT series followed the same trajectory — GPT-2 seemed impressive, but GPT-3 was a game-changer, boasting 175 billion parameters. And then came GPT-4, which, though shrouded in secrecy regarding its exact scale, clearly demonstrated even greater reasoning abilities, outperforming humans on standardized tests like the SAT and the Uniform Bar Exam.
This is the fundamental insight behind the Scaling Laws in AI: throw more data and computation at a model, and it will improve — at least up to a point. Think of it like bodybuilders doubling their calorie intake to bulk up; it works, but only until they hit physiological limits. Similarly, AI researchers are now questioning whether scaling alone can continue delivering improvements or if we’re approaching a plateau where newer architectures will be needed. After all, even the biggest, most swole LLMs have their flaws, and we might need more than just brute force to reach true artificial intelligence.
The Downsides: Ethical Challenges and AI’s Limitations
For all their brilliance, LLMs sometimes resemble that one friend who confidently explains things they barely understand — except LLMs don’t just bluff at parties, they do it in medical reports, legal documents, and academic papers. These so-called “hallucinations” — where AI generates completely false yet highly convincing information — are a serious issue. For instance, Google’s Gemini once confidently fabricated historical facts with generated images, and GPT-4 has been caught inventing legal precedents out of thin air. You wouldn’t trust a lawyer who cites non-existent cases, so why trust an AI that does the same?
Then there’s the age-old issue of bias and toxicity. Since LLMs are trained on vast amounts of internet data, they inherit humanity’s greatest hits — along with its worst mistakes. A 2024 study found that Meta’s LLaMA models exhibited racial and gender biases, and OpenAI has had to implement extensive filtering to prevent harmful outputs in GPT-4. Despite these efforts, AI still occasionally regurgitates harmful stereotypes or misinformation, leading to real-world consequences.
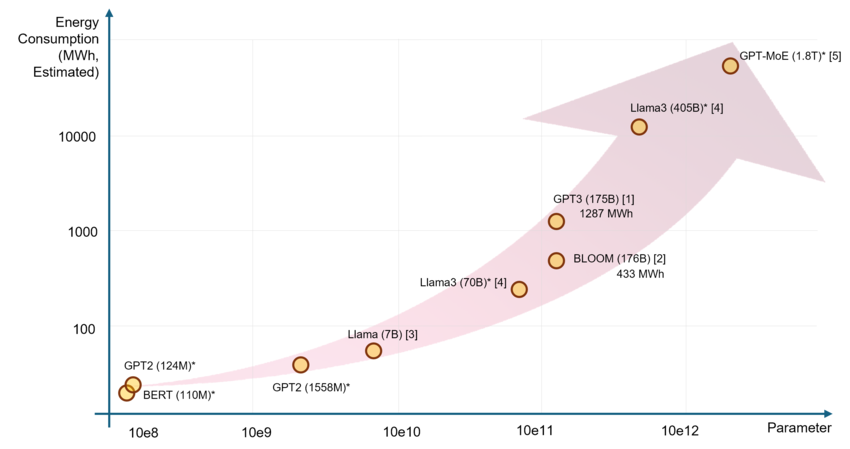
And let’s talk energy consumption. Training a state-of-the-art model isn’t just expensive — it’s an ecological nightmare. GPT-4’s training likely consumed millions of kilowatt-hours, requiring data centers that could power small cities. One study estimated that training a large AI model emits as much carbon as five average cars over their entire lifetime. Sustainable AI? We’re not quite there yet.
The good news? Researchers aren’t sitting idly by. Methods like reinforcement learning from human feedback (RLHF), improved dataset curation, and adversarial testing are being used to curb bias and hallucinations. OpenAI, DeepMind, and Anthropic are exploring techniques to make models more transparent. But the road to ethical AI remains long, winding, and full of unexpected detours — just ask anyone who’s tried to make an AI both powerful and safe at the same time.
Smarter, Sharper, Aligned: RL, RLHF and Reasoning
Another critical dimension in improving and scaling LLMs involves reinforcement learning, reasoning mechanisms, and advanced alignment strategies. Reinforcement Learning with Human Feedback (RLHF) has become a standard in aligning model outputs with human preferences. It’s what made ChatGPT noticeably more coherent and less likely to suggest skydiving without a parachute. OpenAI’s GPT models, Anthropic’s Claude, and Google’s Bard all incorporate variations of RLHF, where models are fine-tuned using comparisons of outputs rated by human annotators.
Even more intriguing is the push toward actual reasoning — not just statistical pattern-matching, but goal-oriented decision-making. DeepMind’s AlphaCode and Google’s Pathways models experiment with modular approaches where models “think” in steps, inspired more by how humans solve problems than how autocomplete works. The integration of external tools, like calculators, databases, or APIs, is also turning static LLMs into dynamic agents capable of planning and executing complex tasks.
What’s Next? The Future Beyond Transformers
Will AI models keep growing until they rival human intelligence (or surpass it)? The debate rages on. Some argue we’re nearing the point where scaling delivers diminishing returns — where adding more parameters is like stuffing extra RAM into an outdated laptop: it helps, but doesn’t fix fundamental limitations. Others believe that with better architectures, we can still push the boundaries further.
One promising approach? Mixture of Experts (MoE) models, which distribute tasks across multiple specialized sub-models, much like an AI think tank where each member has a distinct area of expertise. Google’s Switch Transformer, for example, has demonstrated that MoE architectures can vastly improve efficiency by activating only a fraction of the model at a time. OpenAI and DeepMind are also exploring similar pathways, hinting that MoE might be a way to balance performance and computational cost.
Beyond that, alternative transformer architectures are making waves. Nvidia’s recent announcement of the DGX Spark, a compact AI mini-supercomputer with 128GB RAM and a 20-core Grace Blackwell ARM CPU, is a sign of where things are headed. With a memory bandwidth of 273 GB/s, it’s designed to simplify local AI model deployment — a crucial step as companies shift towards self-hosted and on-premise AI solutions due to regulatory and data protection concerns. Nvidia is doubling down on this trend, providing hardware tailored for enterprise-grade AI applications. Hyena, developed by researchers at Stanford, seeks to replace self-attention with more computationally efficient mechanisms, allowing models to scale without the same exponential energy costs. RWKV, another rising star, blends the best of transformers and recurrent neural networks, aiming to capture long-term dependencies with lower hardware demands.
But the biggest question remains: what happens after LLMs? The shift towards localized AI is already shaping new solutions. These innovations suggest that the AI of the future won’t just be bigger — it will be more modular, distributed, and embedded directly into enterprise operations. Are we heading into a post-LLM era where entirely new paradigms — neuromorphic computing, symbolic AI, or hybrid models — steal the spotlight? IBM’s work on brain-inspired chips, such as TrueNorth, and Intel’s Loihi project suggest that AI hardware might soon mimic biological neurons rather than just brute-force its way through language prediction. Meanwhile, knowledge graphs and hybrid AI approaches are making a comeback, promising more explainable and efficient AI systems.
In short, the future might not belong to transformers alone, and we may soon see AI that is not just a glorified autocomplete, but something closer to true reasoning. — neuromorphic computing, symbolic AI, or hybrid models — steal the spotlight? IBM’s work on brain-inspired chips, the resurgence of knowledge graphs, and increasing investment in AI that blends statistical and rule-based reasoning suggest that the future might not belong to transformers alone. In the next 5–10 years, AI might evolve into something far beyond today’s text generators — perhaps even systems that genuinely understand and reason, rather than just predict the next word in a sentence.
Conclusion
LLMs are the kings of AI right now, but every empire eventually faces a new challenger. While they have revolutionized how we interact with machines, their limitations — bias, hallucinations, energy use — highlight the need for innovation. The next wave of AI models may be smarter, more efficient, and even more aligned with human values. Only time can answer.
One thing’s for sure: the future of AI is going to be one hell of a ride.